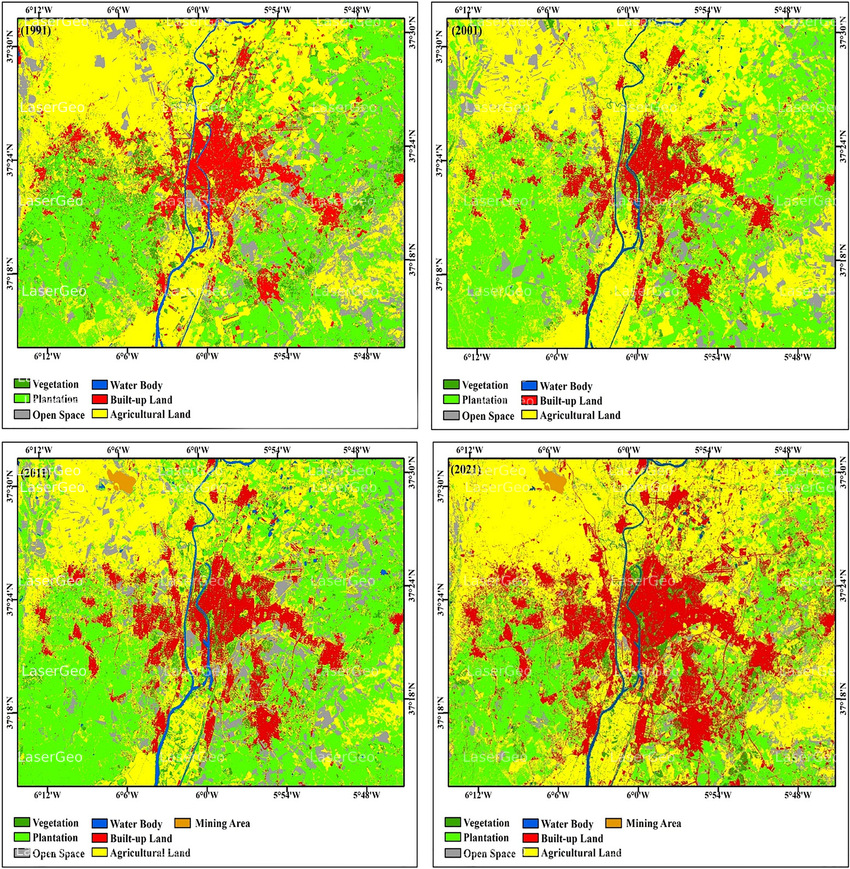
Image classification is a process that involves categorizing the features in a multiband raster image into distinct classes. These classified images are then used to create thematic maps that visually represent the data. Based on the level of interaction between the analyst and the computational system, image classification can be divided into two main approaches: supervised and unsupervised.
Supervised Classification: A Targeted Approach
In supervised classification, the analyst actively selects specific areas of the image, referred to as training data, and assigns them to predefined categories such as roads, water bodies, vegetation, or buildings. These samples are then used to generate statistical patterns or models that are applied across the entire image to classify it. Common techniques for supervised classification include the “maximum likelihood” and “minimum distance” methods, both of which utilize the training data to achieve accurate categorization.
Unsupervised Classification: Automating the Process
Unsupervised classification eliminates the need for pre-identified training data, relying instead on automated algorithms to analyse and cluster the image data into distinct categories during processing. By identifying patterns or similarities within the image, algorithms like “K-means clustering” and “ISODATA” can effectively classify image characteristics without direct human input. This makes it a powerful option for initial exploratory analysis of large datasets.